
Description
Statistical machine learning for text classification with scikit-learn
Presented by Olivier Grisel
The goal of this talk is to give a state-of-the-art overview of machine learning algorithms applied to text classification tasks ranging from language and topic detection in tweets and web pages to sentiment analysis in consumer products reviews.
Abstract
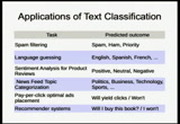
Unstructured or semi-structured text data is ubiquitous thanks to the read- write nature of the web. However human authors are often lazy and don't fill- in structured metadata forms in web applications. It is however possible to automate some structured knowledge extraction with simple and scalable statistical learning tools implemented in python. For instance:
- guessing the language and topic of tweets and web pages
- analyze the sentiment (positive or negative) in consumer products reviews in blogs or customer emails
This talk will introduce the main operational steps of supervised learning:
- extracting the relevant features from text documents
- selecting the right machine learning algorithm to train a model for the task at hand
- using the trained model on previously unseen documents
- evaluating the predictive accuracy of the trained model
We will also demonstrate the results obtained for above tasks using the scikit-learn package and compare it to other implementations such as nltk and the Google Prediction API.